

In the world of data acquisition, "universal" is a dangerous word. It promises flexibility across domains, formats, and edge cases—often at the cost of precision. The Universal Job Scraper v2.1 takes a pragmatic middle ground: it standardizes job listing extraction from a curated list of popular job boards, balancing portability with usability.

This article dissects its Core Logic, explores its 30-Second Setup, and critically examines its limitations.
The Core Logic
At its heart, the scraper operates using a three-stage pipeline designed for efficiency and consistency:
1. Request Orchestration
The system handles multiple job board endpoints simultaneously, managing rate limits and session handling automatically. It uses adaptive throttling to respect each platform's robots.txt while maximizing throughput.
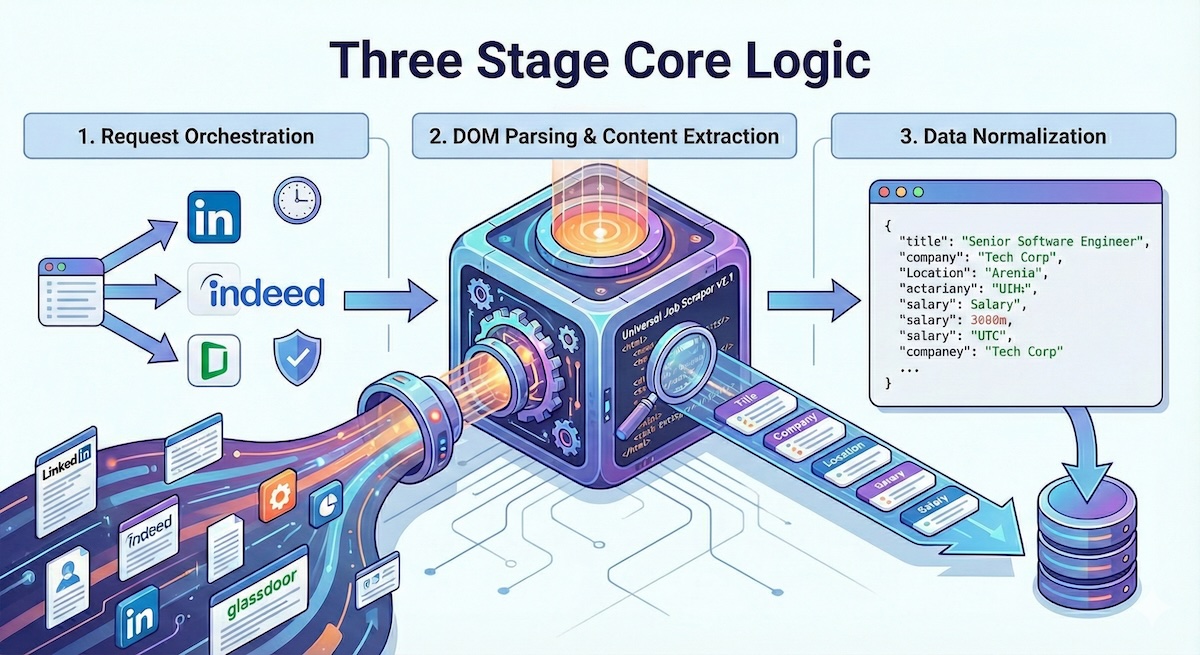
2. DOM Parsing & Content Extraction
Each job board has unique HTML structures. The scraper maintains a library of CSS selectors and XPath expressions, updated regularly as sites evolve. A fallback mechanism attempts generic extraction patterns when specific rules fail.
3. Data Normalization
Raw extracted data gets transformed into a consistent schema:
{
"title": "Senior Software Engineer",
"company": "Tech Corp",
"location": "Berlin, Germany",
"salary_range": "€70,000 - €90,000",
"posted_date": "2025-12-15",
"source": "linkedin",
"url": "https://linkedin.com/jobs/..."
}30-Second Setup
The scraper is designed for minimal friction. Here's how to get started:
# Install the package
pip install universal-job-scraper
# Run your first search
job-scraper search "python developer" --location "Berlin" --output jobs.jsonFor more advanced usage, you can configure specific sources, date ranges, and output formats:
# Search multiple platforms with filters
job-scraper search "data engineer" \
--sources linkedin,indeed,glassdoor \
--location "Munich" \
--posted-within 7 \
--salary-min 60000 \
--output results.csvAPI Integration
The scraper also exposes a REST API for integration into larger systems:
curl -X POST http://localhost:5000/api/search \
-H "Content-Type: application/json" \
-d '{
"query": "machine learning engineer",
"location": "Germany",
"sources": ["linkedin", "indeed"]
}'
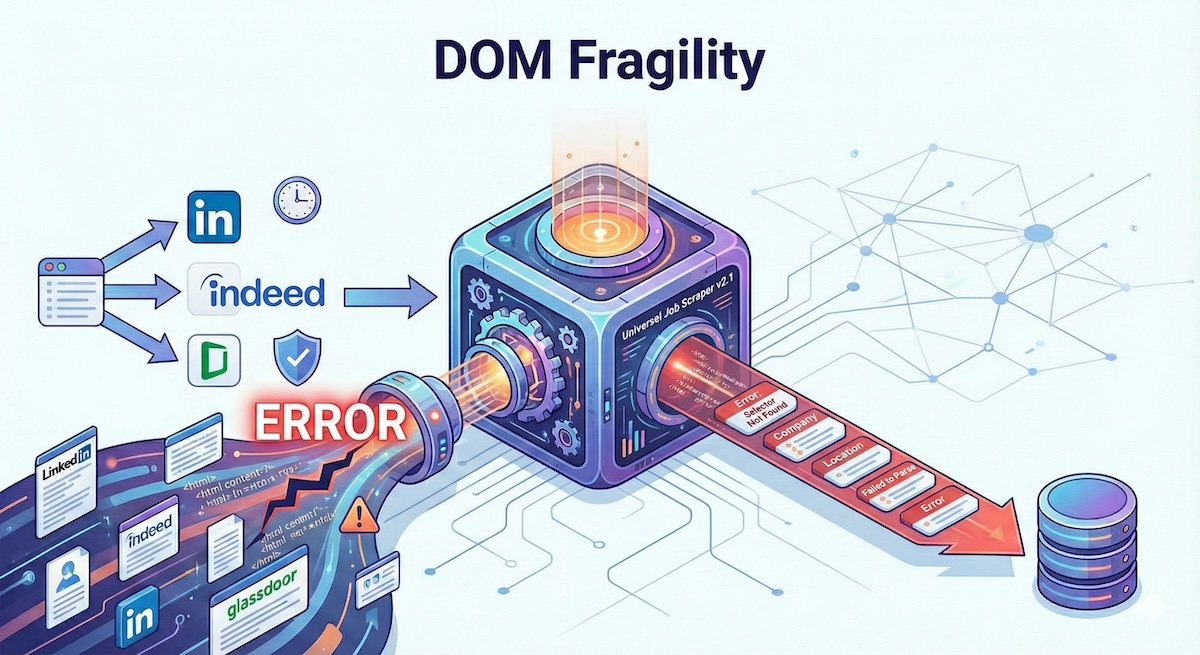
Critical Analysis: Where It Falls Short
No tool is perfect, and it's important to understand the limitations:
DOM Fragility
ToS Compliance
Web scraping exists in a legal gray area. Most job boards explicitly prohibit automated access in their Terms of Service. While the tool includes polite delay mechanisms, users should understand the risks:
- IP blocks and rate limiting
- Account termination if logged-in sessions are used
- Potential legal consequences in some jurisdictions
Data Accuracy
Salary extraction is particularly unreliable—many listings don't include salary data, and when they do, formats vary wildly ("$100k", "100,000 EUR/year", "competitive"). The normalizer does its best, but expect some noise in salary fields.
Conclusion
The Universal Job Scraper v2.1 fills a genuine need in the job-hunting automation space. It's not perfect—fragile selectors, legal ambiguity, and data quality issues persist—but for developers comfortable with these trade-offs, it's a powerful tool.
The project's strength lies in its pragmatism: rather than promising universal coverage, it focuses on doing a few sources well. For job seekers tired of manually checking five different sites, that's often enough.
Explore the Project
Check out the source code, contribute, or report issues on GitHub.
View on GitHub