

In der Welt der Datenerfassung ist „universal" ein gefährliches Wort. Es verspricht Flexibilität über Domänen, Formate und Grenzfälle hinweg – oft auf Kosten der Präzision. Der Universal Job Scraper v2.1 wählt einen pragmatischen Mittelweg: Er standardisiert die Extraktion von Stellenangeboten von einer kuratierten Liste beliebter Jobbörsen und balanciert Portabilität mit Benutzerfreundlichkeit.

Dieser Artikel analysiert die Kernlogik, erkundet das 30-Sekunden-Setup und untersucht kritisch seine Grenzen.
Die Kernlogik
Im Kern arbeitet der Scraper mit einer dreistufigen Pipeline, die auf Effizienz und Konsistenz ausgelegt ist:
1. Request-Orchestrierung
Das System verarbeitet mehrere Jobbörsen-Endpunkte gleichzeitig und verwaltet automatisch Rate-Limits und Session-Handling. Es verwendet adaptive Drosselung, um die robots.txt jeder Plattform zu respektieren und gleichzeitig den Durchsatz zu maximieren.
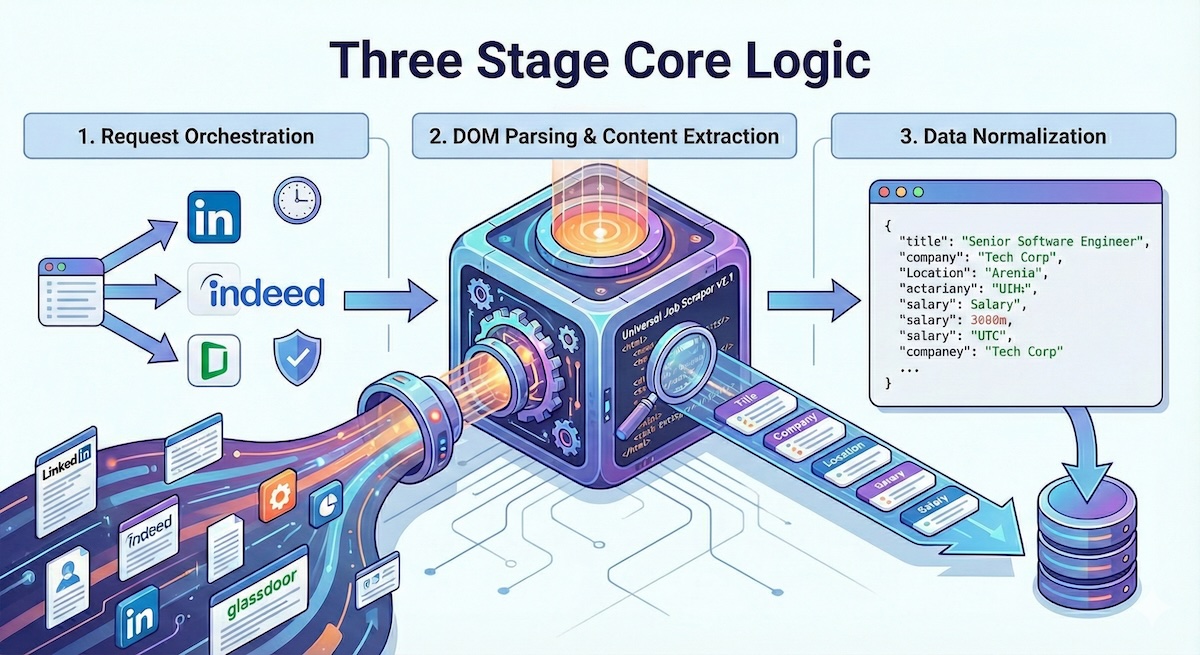
2. DOM-Parsing & Inhaltsextraktion
Jede Jobbörse hat einzigartige HTML-Strukturen. Der Scraper pflegt eine Bibliothek von CSS-Selektoren und XPath-Ausdrücken, die regelmäßig aktualisiert werden, wenn sich die Seiten weiterentwickeln.
3. Datennormalisierung
Rohe extrahierte Daten werden in ein konsistentes Schema transformiert:
{
"title": "Senior Software Engineer",
"company": "Tech Corp",
"location": "Berlin, Deutschland",
"salary_range": "€70.000 - €90.000",
"posted_date": "2025-12-15",
"source": "linkedin",
"url": "https://linkedin.com/jobs/..."
}30-Sekunden-Setup
Der Scraper ist für minimale Reibung konzipiert. So starten Sie:
# Paket installieren
pip install universal-job-scraper
# Erste Suche ausführen
job-scraper search "python developer" --location "Berlin" --output jobs.jsonFür fortgeschrittene Nutzung können Sie spezifische Quellen, Datumsbereiche und Ausgabeformate konfigurieren:
# Mehrere Plattformen mit Filtern durchsuchen
job-scraper search "data engineer" \
--sources linkedin,indeed,glassdoor \
--location "München" \
--posted-within 7 \
--salary-min 60000 \
--output results.csvAPI-Integration
Der Scraper bietet auch eine REST-API für die Integration in größere Systeme:
curl -X POST http://localhost:5000/api/search \
-H "Content-Type: application/json" \
-d '{
"query": "machine learning engineer",
"location": "Deutschland",
"sources": ["linkedin", "indeed"]
}'
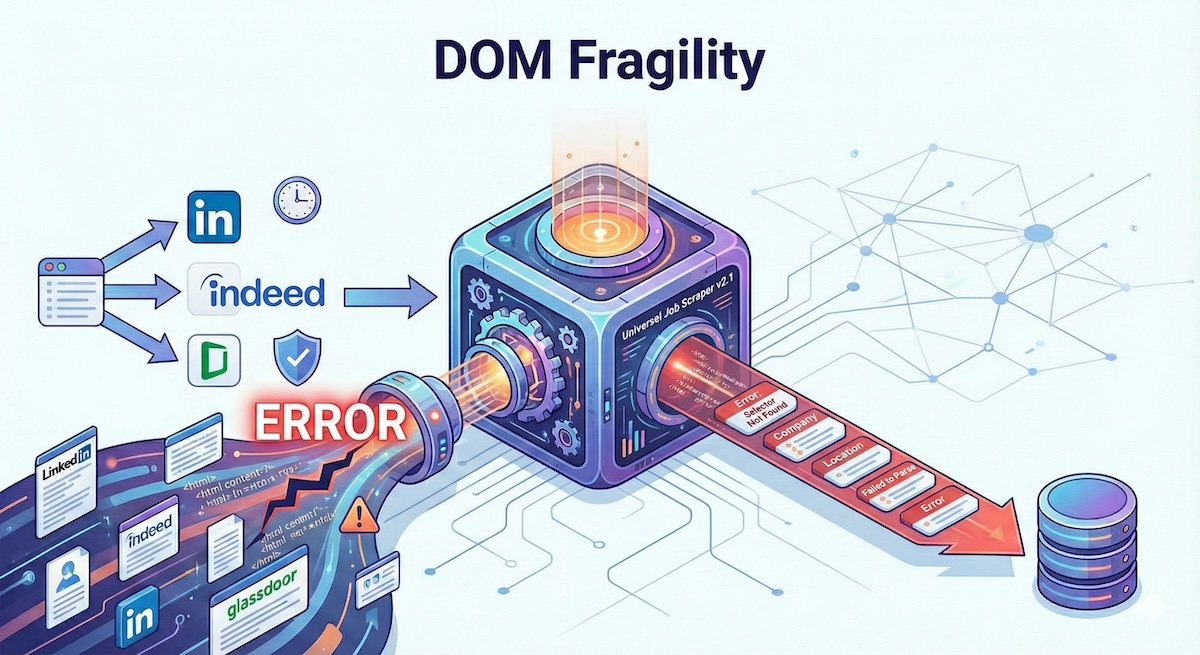
Kritische Analyse: Wo es Schwächen gibt
Kein Tool ist perfekt, und es ist wichtig, die Grenzen zu verstehen:
DOM-Fragilität
ToS-Konformität
Web-Scraping existiert in einer rechtlichen Grauzone. Die meisten Jobbörsen verbieten automatisierten Zugriff ausdrücklich in ihren Nutzungsbedingungen.
- IP-Sperren und Rate-Limiting
- Kontokündigung bei Nutzung eingeloggter Sessions
- Mögliche rechtliche Konsequenzen in einigen Rechtsordnungen
Datengenauigkeit
Die Gehaltsextraktion ist besonders unzuverlässig – viele Anzeigen enthalten keine Gehaltsdaten, und wenn doch, variieren die Formate stark.
Fazit
Der Universal Job Scraper v2.1 füllt einen echten Bedarf im Bereich der Automatisierung der Jobsuche. Er ist nicht perfekt – fragile Selektoren, rechtliche Unklarheiten und Datenqualitätsprobleme bestehen weiterhin – aber für Entwickler, die mit diesen Kompromissen umgehen können, ist es ein leistungsstarkes Werkzeug.
Die Stärke des Projekts liegt in seinem Pragmatismus: Anstatt universelle Abdeckung zu versprechen, konzentriert es sich darauf, wenige Quellen gut zu bedienen.
Projekt erkunden
Schauen Sie sich den Quellcode an, tragen Sie bei oder melden Sie Probleme auf GitHub.
Auf GitHub ansehen