


Die meisten Entwickler versuchen, KI-Fehler zu beheben, indem sie längere, komplexere System-Prompts schreiben. Sie fügen Regeln hinzu wie „Verwende kein Wix für SaaS-Apps" oder „Empfehle immer Bubble für Marktplätze."
Dieser Ansatz ist grundlegend fehlerhaft. Mit wachsendem Regelwerk wird der Prompt unhandlich, die Token-Kosten steigen und die Aufmerksamkeit des Modells verwässert, was zu „Instruction Drift" führt.
Diese Anleitung führt durch den Aufbau einer automatisierten Pipeline mit n8n und Supabase, bei der Sie die KI einfach durch Hinzufügen einer Zeile in einer Tabelle „trainieren" können.
Die Architektur
Wir benötigen drei Komponenten, um die Logik (Prompt) vom Wissen (Beispiele) zu entkoppeln:
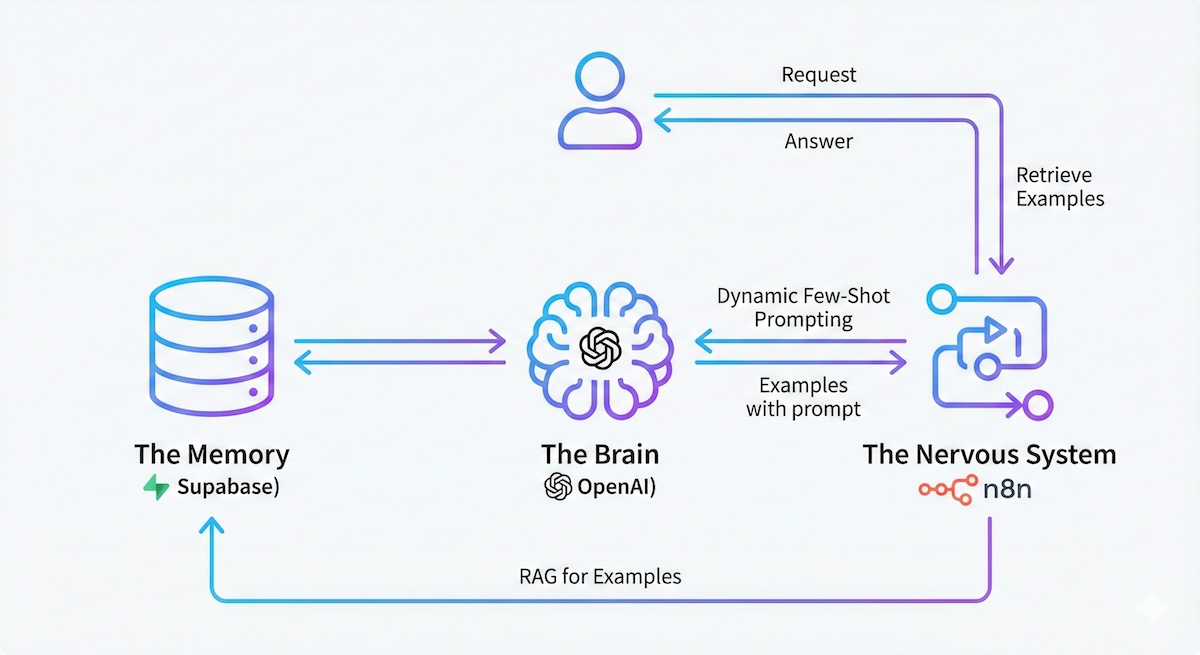
- Das Gehirn (OpenAI): Zum Generieren von Embeddings und finalen Antworten.
- Das Gedächtnis (Supabase): Eine Vektordatenbank, die „Problem → Lösung"-Paare speichert.
- Das Nervensystem (n8n): Orchestriert den Datenfluss zwischen Benutzer, DB und LLM.
Warum das funktioniert
LLMs sind Muster-Matcher, keine Logik-Engines. Wenn Sie dem Modell zeigen, wie Sie ein ähnliches Problem in der Vergangenheit gelöst haben, ahmt es das Muster nach. Das ist mathematisch robuster, als die Logik in abstraktem englischem Text zu beschreiben.
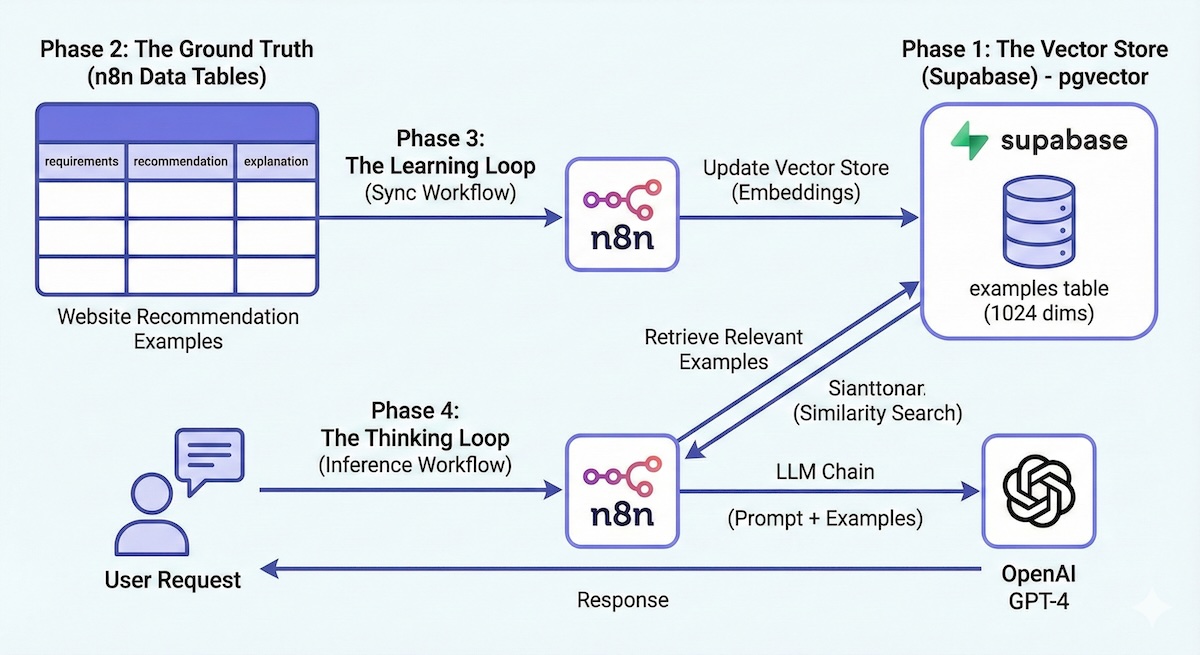
Phase 1: Der Vector Store (Supabase)
Wir brauchen eine Datenbank, die die „semantische Bedeutung" einer Anforderung versteht, nicht nur Keyword-Matching.
- Erstellen Sie ein Projekt bei Supabase.
- Navigieren Sie zum SQL Editor und führen Sie das folgende Setup-Skript aus.
text-embedding-3-large Modell übereinzustimmen.
-- 1. Vector Extension aktivieren
create extension if not exists vector;
-- 2. Speichertabelle erstellen
create table examples (
id uuid primary key,
content text, -- Die "User Requirement" (was gesucht wird)
metadata jsonb, -- Der vollständige Kontext (Empfehlung + Erklärung)
embedding vector(1024) -- MUSS deinen eingebeteten Model Ausmaßen entsprechen
);
-- 3. Ähnlichkeitssuchfunktion erstellen
create or replace function relevant_examples (
query_embedding vector(1024),
match_threshold float,
match_count int
)
returns table (
id uuid,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
begin
return query
select
examples.id,
examples.content,
examples.metadata,
1 - (examples.embedding <=> query_embedding) as similarity
from examples
where 1 - (examples.embedding <=> query_embedding) > match_threshold
order by examples.embedding <=> query_embedding
limit match_count;
end;
$$;Phase 2: Die Ground Truth (n8n Data Tables)
Anstatt Vektoren direkt zu verwalten, verwenden wir n8ns interne Data Tables als unser CMS.
- Erstellen Sie in n8n eine Data Table namens
Website Recommendation Examples. - Fügen Sie drei String-Spalten hinzu:
requirements(Das Eingabeszenario)recommendation(Die korrekte Ausgabe)explanation(Die „Chain of Thought")
Seed-Daten: Fügen Sie 10-15 unterschiedliche Beispiele hinzu.
- Zeile 1: „Einfaches Portfolio für einen Fotografen" → „Squarespace"
- Zeile 2: „Multi-Vendor-Marktplatz wie Airbnb" → „Bubble oder Sharetribe"
Phase 3: Der Lernzyklus (Synchronisierter Workflow)
Wir benötigen einen Workflow, der die n8n-Tabelle überwacht und den Supabase-Vektorspeicher aktualisiert. Dadurch wird sichergestellt, dass die KI neue „Lektionen“ automatisch lernt, sobald diese hinzugefügt werden.
- Auslöser: Zeitplan (täglich)
- Zeilen abrufen (n8n-Tabelle): Alle Zeilen abrufen, die
updatedAtaktuell sind (z. B. die letzten 48 Stunden). - Elemente durchlaufen: Bearbeiten Sie jeweils ein Beispiel.
- Alte Version löschen (Supabase):
Entscheidender Schritt Bevor Sie das aktualisierte Beispiel hinzufügen, löschen Sie bitte alle vorhandenen Zeilen mit der gleichen ID, um Duplikate zu vermeiden.
- Dokument hinzufügen (Supabase Vector Store):
- Modell:
text-embedding-3-large - Abmessungen:
1024 - Mapping Daten:
- Seiteninhalt →
requirements(Das ist es, was wir einbetten). - Metadaten → Das vollständige Objekt zuordnen (
id,recommendation,explanation).
- Seiteninhalt →
- Modell:
Phase 4: Die Denkschleife (Inferenz-Workflow)
Dies ist der Live-Agent, der auf Benutzeranfragen antwortet.
- Auslöser: Chat oder Webhook (Input:
user_requirements) - Abrufen (Supabase Vector Store):
- Operation: Get Many (Abrufen sortierter Dokumente).
- Abfrage:
{{ $trigger.user_requirements }} - Limit:
4 - Funktions Name:
relevant_examples
- Formatkontext (Code Node): Nimm die 4 JSON-Ergebnisse und wandle sie in einen String um.
- LLM Chain (OpenAI GPT-4):
System Prompt:
Sie sind ein Experte für Webseitenempfehlungen.
Um Ihnen die Beantwortung der Benutzeranfrage zu erleichtern, finden Sie hier Beispiele dafür, wie wir ähnliche Anfragen in der Vergangenheit bearbeitet haben:
{{ $json.formatted_examples }}
Analysieren Sie die Anfrage des Nutzers anhand dieser Präzedenzfälle:
Benutzeranfrage: {{ $trigger.user_requirements }}Das „Teaching"-Paradigma
Die Schönheit dieses Systems liegt darin, wie Sie mit Fehlern umgehen.
Wenn der Benutzer nach einer „Komplexen SaaS-App" fragt und die KI fälschlicherweise „Wix" empfiehlt:
Aktion: Gehen Sie zu Ihrer n8n Data Table. Fügen Sie eine neue Zeile hinzu:
- Requirement: „Aufbau einer komplexen SaaS-App mit Auth und Datenbank."
- Recommendation: „Bubble oder Custom Code."
- Explanation: „Wix ist auf statische Inhalte und einfachen E-Commerce beschränkt; SaaS-Logik erfordert ein dediziertes Backend."

Beim nächsten Sync-Lauf wird dieser Vektor hinzugefügt. Wenn ein Benutzer eine ähnliche Frage stellt, ruft das System diese spezifische Korrektur ab und gibt die richtige Antwort.

Kritische Analyse
Obwohl leistungsfähig, hat dieser „Managed Memory"-Ansatz Kompromisse:
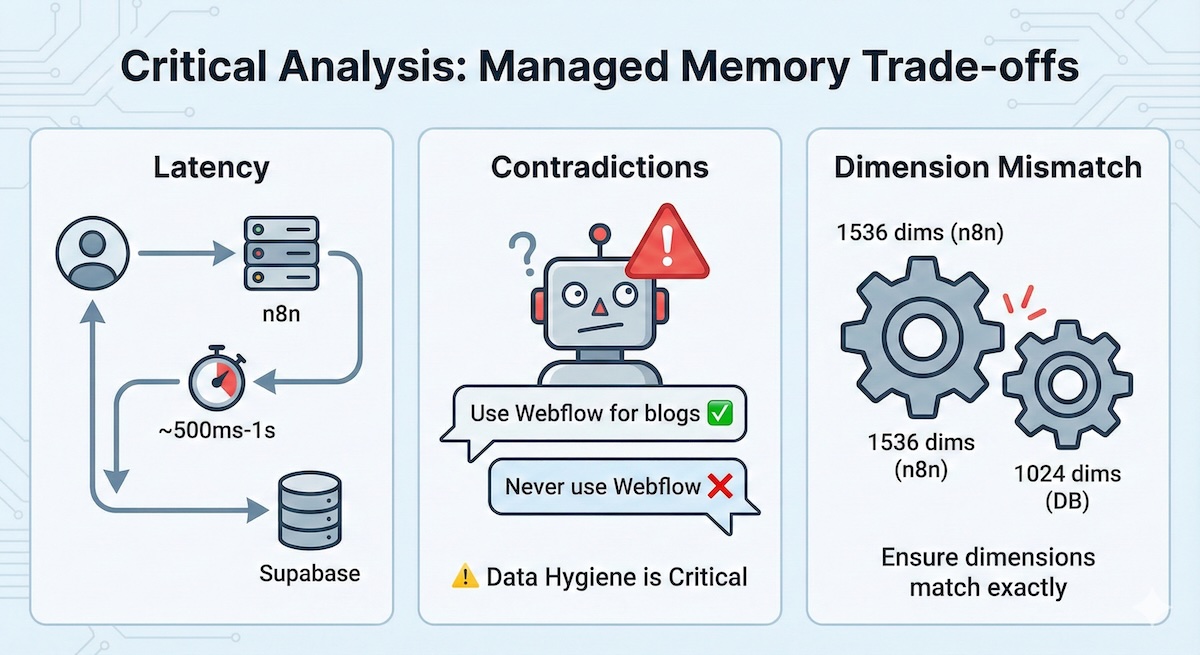
Latenz
Der zusätzliche Hop zu Supabase und die Embedding-Generierung fügen ~500ms-1s zur Antwortzeit hinzu.
Widersprüche
Fazit
Diese Architektur bewegt Sie vom „KI-Konsumenten" zum „KI-Architekten" – Sie bauen Systeme, die sich durch Datenkuration im Laufe der Zeit verbessern, anstatt durch endloses Prompt-Tweaking.
Bereit, Ihr eigenes zu bauen?
Starten Sie mit n8n und Supabase, um selbstverbessernde KI-Agenten zu erstellen.
Kontakt aufnehmen